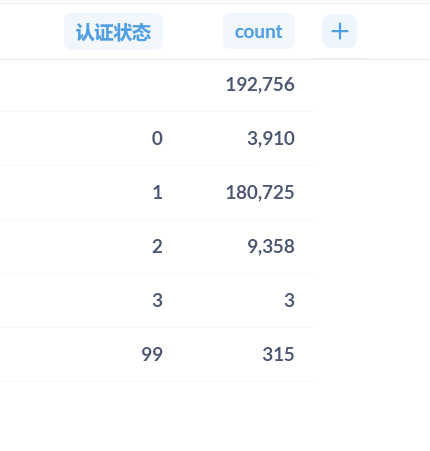
// ==UserScript==
// @name 虎嗅评论过滤 - 屏蔽评论数超过100页的用户
// @namespace http://tampermonkey.net/
// @version 1.0.1
// @description 自动检测并屏蔽评论数超过100页的用户评论
// @author You
// @match https://www.huxiu.com/moment/*
// @exclude https://www.huxiu.com/member/*
// @grant GM_xmlhttpRequest
// @connect api-web-account.huxiu.com
// ==/UserScript==
(function() {
'use strict';
// 配置
const MAX_PAGES = 100; // 最大允许的评论页数
const API_URL = 'https://api-web-account.huxiu.com/web/comment/commentList';
const CHECK_INTERVAL = 2000; // 检查新评论的间隔(毫秒)
// 存储正在检查中的用户ID,避免重复请求
const pendingChecks = new Set();
/**
* 从评论元素中提取用户ID
*/
function extractUserId(commentElement) {
// 尝试多种方式提取用户ID
// 方式1: 从虎嗅会员链接中提取(最常见,格式:/member/2374684.html)
const userLinks = commentElement.querySelectorAll('a[href*="/member/"]');
for (const link of userLinks) {
const href = link.getAttribute('href');
// 匹配 /member/123456.html 或 /member/123456 格式
let match = href.match(/\/member\/(\d+)(?:\.html)?/);
if (match) return match[1];
}
// 方式2: 从其他用户链接格式中提取
const otherLinks = commentElement.querySelectorAll('a[href*="/user/"], a[href*="uid="]');
for (const link of otherLinks) {
const href = link.getAttribute('href');
// 匹配 /user/123456 格式
let match = href.match(/\/user\/(\d+)/);
if (match) return match[1];
// 匹配 ?uid=123456 格式
match = href.match(/[?&]uid=(\d+)/);
if (match) return match[1];
}
// 方式2: 从data属性中提取
let element = commentElement;
for (let i = 0; i < 10 && element; i++) {
const dataUid = element.getAttribute('data-uid') ||
element.getAttribute('data-user-id') ||
element.getAttribute('uid');
if (dataUid && /^\d+$/.test(dataUid)) {
return dataUid;
}
element = element.parentElement;
}
// 方式3: 从class或id中提取
element = commentElement;
for (let i = 0; i < 5 && element; i++) {
const uidMatch = element.className?.match(/uid[_-]?(\d+)|user[_-]?(\d+)/i) ||
element.id?.match(/uid[_-]?(\d+)|user[_-]?(\d+)/i);
if (uidMatch) {
return uidMatch[1] || uidMatch[2];
}
element = element.parentElement;
}
// 方式4: 从图片src或其他属性中提取
const img = commentElement.querySelector('img[src*="user"], img[src*="avatar"]');
if (img) {
const src = img.getAttribute('src');
const match = src?.match(/user[\/_-]?(\d+)/i);
if (match) return match[1];
}
// 调试:输出元素信息
console.warn('无法提取用户ID,元素信息:', {
className: commentElement.className,
id: commentElement.id,
innerHTML: commentElement.innerHTML.substring(0, 200)
});
return null;
}
/**
* 获取用户评论总数
*/
function getUserCommentPages(uid) {
return new Promise((resolve, reject) => {
// 如果正在检查中,等待
if (pendingChecks.has(uid)) {
setTimeout(() => {
getUserCommentPages(uid).then(resolve).catch(reject);
}, 500);
return;
}
pendingChecks.add(uid);
GM_xmlhttpRequest({
method: 'POST',
url: API_URL,
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'application/json',
'Referer': 'https://www.huxiu.com/',
'Origin': 'https://www.huxiu.com'
},
data: `platform=www&page=1&uid=${uid}`,
onload: function(response) {
pendingChecks.delete(uid);
try {
const data = JSON.parse(response.responseText);
// 调试:输出API响应结构
console.log(`[API] 用户 ${uid} 的API响应:`, JSON.stringify(data, null, 2));
// 尝试多种可能的响应格式
let totalPages = 0;
if (data && data.data) {
// 格式1: 虎嗅API标准格式 { data: { total_page: xxx } }
if (data.data.total_page !== undefined && data.data.total_page !== null) {
totalPages = parseInt(data.data.total_page);
console.log(`[API] 从 data.data.total_page 获取页数: ${totalPages}`);
} else {
console.warn(`[API] 用户 ${uid} 的响应中未找到 total_page 字段,data.data 内容:`, data.data);
}
} else {
console.warn(`[API] 用户 ${uid} 的响应格式异常,data 或 data.data 不存在:`, data);
}
if (totalPages === 0) {
console.warn(`[API] 用户 ${uid} 的页数解析为0,可能解析失败`);
}
resolve(totalPages);
} catch (e) {
console.error('解析API响应失败:', e, response.responseText);
reject(e);
}
},
onerror: function(error) {
pendingChecks.delete(uid);
console.error('API请求失败:', error);
reject(error);
}
});
});
}
/**
* 隐藏评论元素
* @param {HTMLElement} commentElement - 评论元素(单个评论项)
* @param {string} uid - 用户ID
* @param {number} totalPages - 总评论页数
*/
function hideComment(commentElement, uid, totalPages) {
// 确保只隐藏单个评论项,而不是整个列表
// 检查是否是评论列表容器
if (commentElement.classList.contains('moment-comment__list')) {
console.warn(`警告:尝试隐藏评论列表容器,跳过。用户ID: ${uid}`);
return;
}
// 只隐藏单个评论项
commentElement.style.display = 'none';
commentElement.setAttribute('data-filtered', 'true');
// 在控制台输出屏蔽信息
console.log(`🚫 已屏蔽用户评论 | 用户ID: ${uid} | 总评论页数: ${totalPages}页`);
// 添加一个简单的提示标记,显示评论已被隐藏
const marker = document.createElement('div');
marker.style.cssText = 'padding: 8px 12px; background: #f5f5f5; color: #999; font-size: 12px; margin-bottom: 10px; border-left: 3px solid #ddd; border-radius: 2px;';
marker.textContent = '该评论已隐藏';
marker.setAttribute('data-filter-marker', 'true');
// 插入到评论项的父容器中,替换被隐藏的评论项位置
if (commentElement.parentNode) {
commentElement.parentNode.insertBefore(marker, commentElement);
}
}
/**
* 检查并过滤单个评论
*/
async function checkAndFilterComment(commentElement) {
// 如果已经处理过,跳过
if (commentElement.getAttribute('data-checked') === 'true' ||
commentElement.getAttribute('data-filtered') === 'true') {
return;
}
// 安全检查:确保是单个评论项,而不是评论列表容器
if (commentElement.classList.contains('moment-comment__list')) {
console.warn('跳过评论列表容器,只处理单个评论项');
return;
}
const uid = extractUserId(commentElement);
if (!uid) {
console.warn('无法提取用户ID:', commentElement);
return;
}
// 标记为已检查
commentElement.setAttribute('data-checked', 'true');
try {
const totalPages = await getUserCommentPages(uid);
console.log(`用户 ${uid} 的评论页数: ${totalPages}`);
if (totalPages > MAX_PAGES) {
hideComment(commentElement, uid, totalPages);
}
} catch (error) {
console.error(`检查用户 ${uid} 失败:`, error);
// 出错时不隐藏,避免误杀
}
}
/**
* 查找页面上的所有评论元素
*/
function findAllComments() {
// 根据虎嗅网站的实际结构,只选择单个评论项
// 优先使用最精确的选择器,避免选择到评论列表容器
const selectors = [
'.comment-item', // 虎嗅单个评论项的标准选择器
'[data-comment-id]', // 通过data-comment-id属性的单个评论项
];
const comments = new Set();
for (const selector of selectors) {
try {
const elements = document.querySelectorAll(selector);
elements.forEach(el => {
// 确保不是已经过滤的元素,且有实际内容
// 排除评论列表容器(.moment-comment__list)
if (el.getAttribute('data-filtered') !== 'true' &&
!el.classList.contains('moment-comment__list') && // 排除列表容器
el.offsetHeight > 0 && // 确保元素可见
el.textContent.trim().length > 0) { // 确保有内容
comments.add(el);
}
});
} catch (e) {
// 忽略无效选择器
}
}
// 去重:如果元素A包含元素B,只保留最内层的元素(单个评论项)
const filtered = Array.from(comments).filter(comment => {
// 如果这个元素包含其他评论元素,说明它是容器,应该排除
const hasChildComment = Array.from(comments).some(other =>
other !== comment && comment.contains(other)
);
// 如果这个元素被其他评论元素包含,保留它(它是单个评论项)
const isChildOfComment = Array.from(comments).some(other =>
other !== comment && other.contains(comment)
);
// 保留:要么是单个评论项(被其他元素包含),要么是独立的评论项(不包含其他评论)
return !hasChildComment || isChildOfComment;
});
return filtered;
}
/**
* 批量检查评论
*/
async function checkAllComments() {
const comments = findAllComments();
console.log(`找到 ${comments.length} 条评论,开始检查...`);
// 批量处理,避免同时发起太多请求
const batchSize = 5;
for (let i = 0; i < comments.length; i += batchSize) {
const batch = comments.slice(i, i + batchSize);
await Promise.all(batch.map(comment => checkAndFilterComment(comment)));
// 批次之间稍作延迟
if (i + batchSize < comments.length) {
await new Promise(resolve => setTimeout(resolve, 500));
}
}
}
/**
* 监听DOM变化,处理动态加载的评论
*/
function setupMutationObserver() {
const observer = new MutationObserver((mutations) => {
let shouldCheck = false;
mutations.forEach((mutation) => {
mutation.addedNodes.forEach((node) => {
if (node.nodeType === 1) { // Element node
// 检查是否是评论相关的元素
if (node.classList && (
node.classList.toString().includes('comment') ||
node.querySelector && node.querySelector('[class*="comment"]')
)) {
shouldCheck = true;
}
}
});
});
if (shouldCheck) {
// 延迟检查,等待DOM完全渲染
setTimeout(() => {
checkAllComments();
}, 1000);
}
});
observer.observe(document.body, {
childList: true,
subtree: true
});
}
/**
* 初始化
*/
function init() {
// 排除个人中心页面
if (window.location.pathname.match(/^\/member\//)) {
console.log('虎嗅评论过滤插件:跳过个人中心页面');
return;
}
console.log('虎嗅评论过滤插件已启动(无缓存模式)');
// 等待页面加载完成
if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', () => {
setTimeout(checkAllComments, 2000);
setupMutationObserver();
});
} else {
setTimeout(checkAllComments, 2000);
setupMutationObserver();
}
// 定期检查新评论
setInterval(checkAllComments, CHECK_INTERVAL);
}
// 启动
init();
})();
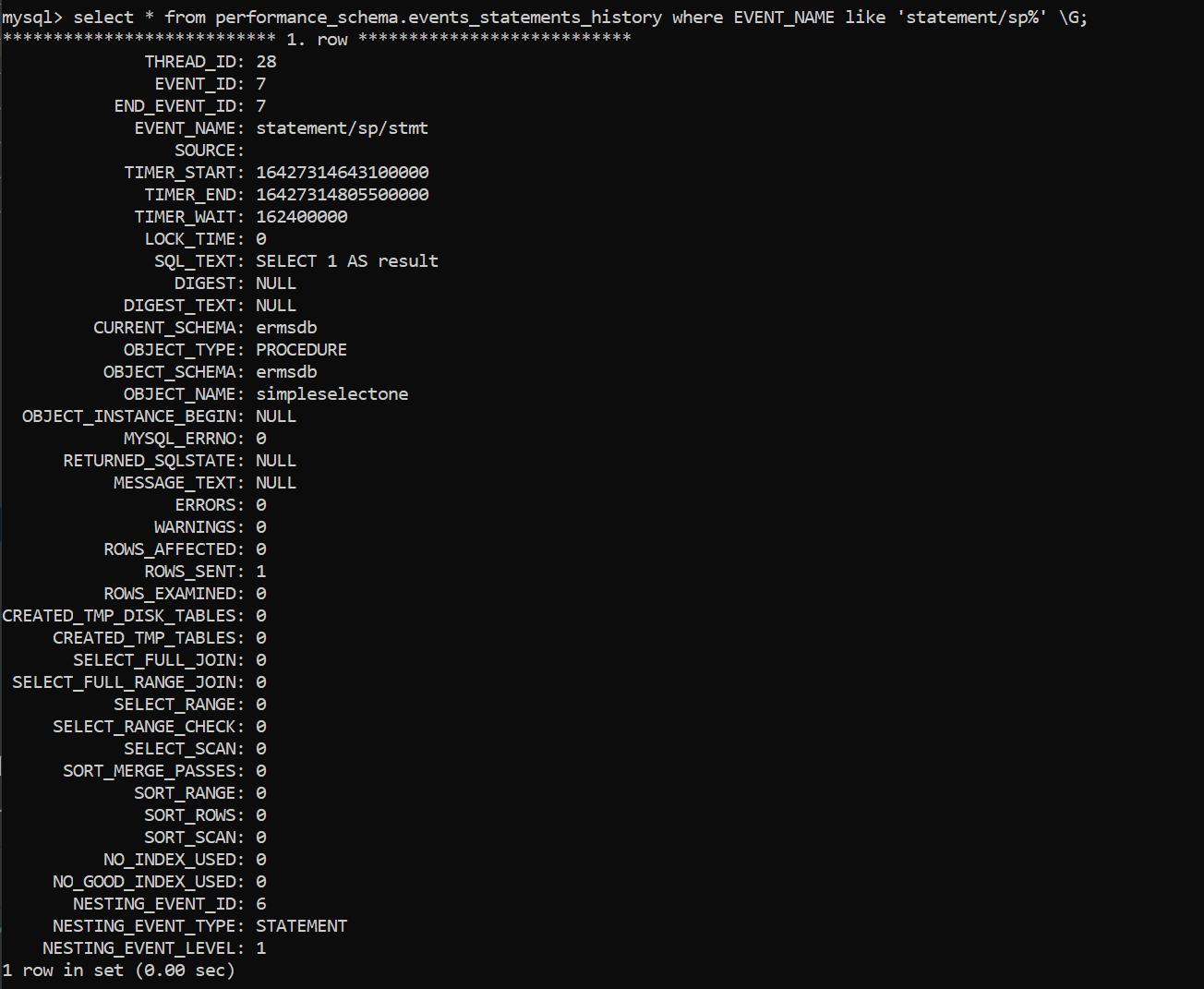
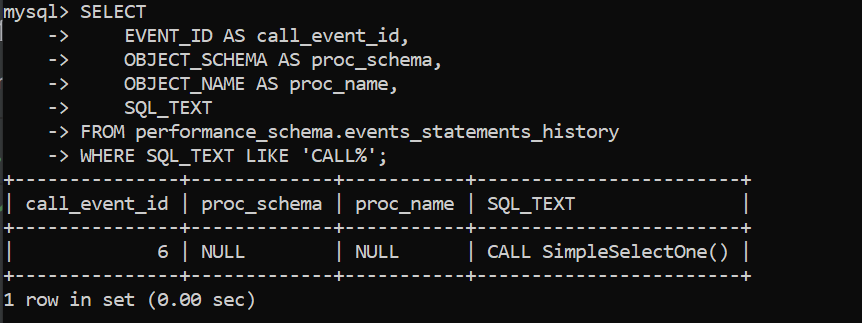

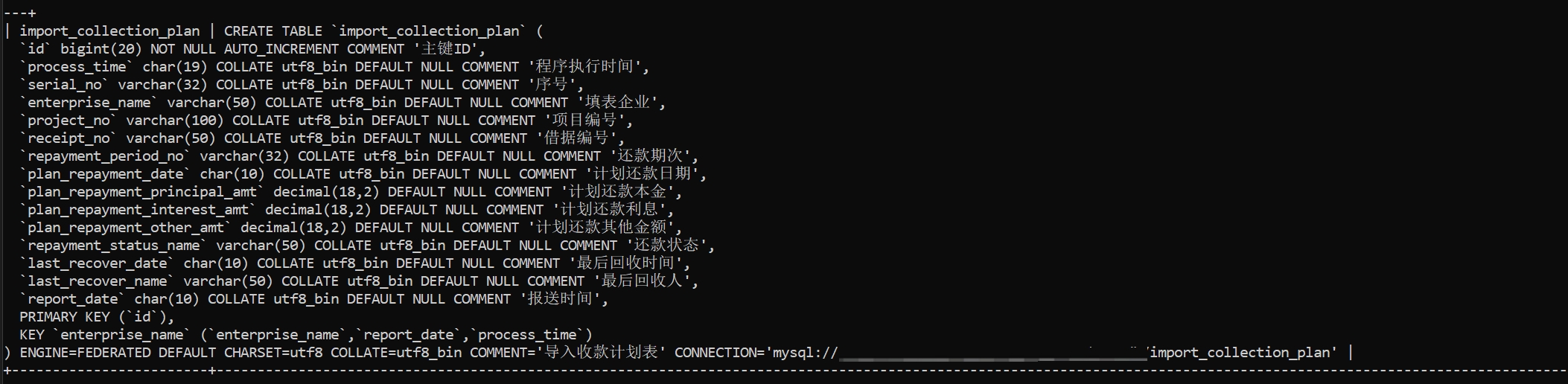

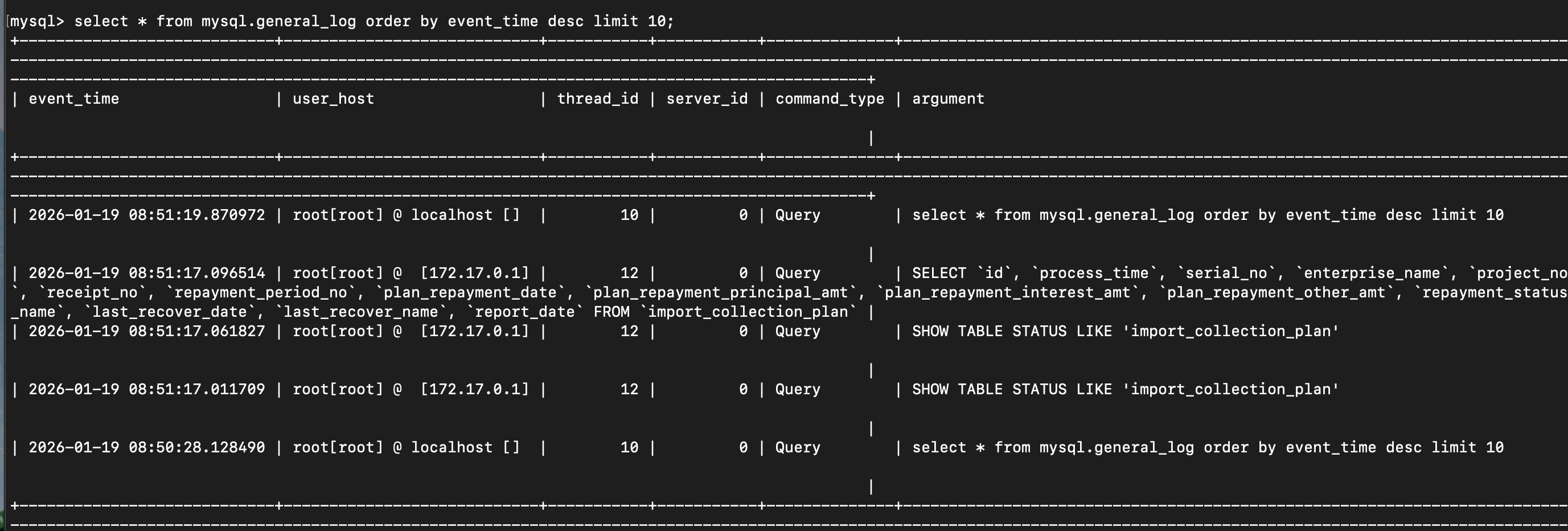

 可以看到这个
可以看到这个